

Dagster OSS is built for builders. But as teams grow, the operational burden of running the platform can quietly consume engineering time. This guide explains when it makes sense to move to Dagster+ and shift your focus back to building data products.
Dagster started as an open source project, and most teams using Dagster+ today began the same way. Companies like Kraft Heinz, Discord, and Booking.com built real, production-grade data platforms before making the move to Dagster+. They did not switch because OSS stopped working. They switched because their teams wanted to focus on the most valuable parts of their data products.
So when does it make sense to move? The honest answer is not a feature checklist. It is a question of where your engineers are spending their time.
Dagster OSS Is Designed for Builders
The appeal of Dagster OSS is well earned. Asset-based orchestration gives you a fundamentally better mental model for data pipelines. You reason about data assets and their dependencies, not just task graphs. It is Python-native, which means you bring your own tooling, abstractions, and infrastructure. Nothing is hidden from you.
For early-stage teams, that control is exactly right. When you are a small team moving fast, you want to own your stack. That ownership is a genuine advantage, until it becomes a second job.
As teams grow, with more engineers, more pipelines, and more stakeholders who depend on data being fresh and correct, the surface area expands quietly. Not in one dramatic moment, but through an accumulation of small burdens.
Dagster+ Is for Scaling
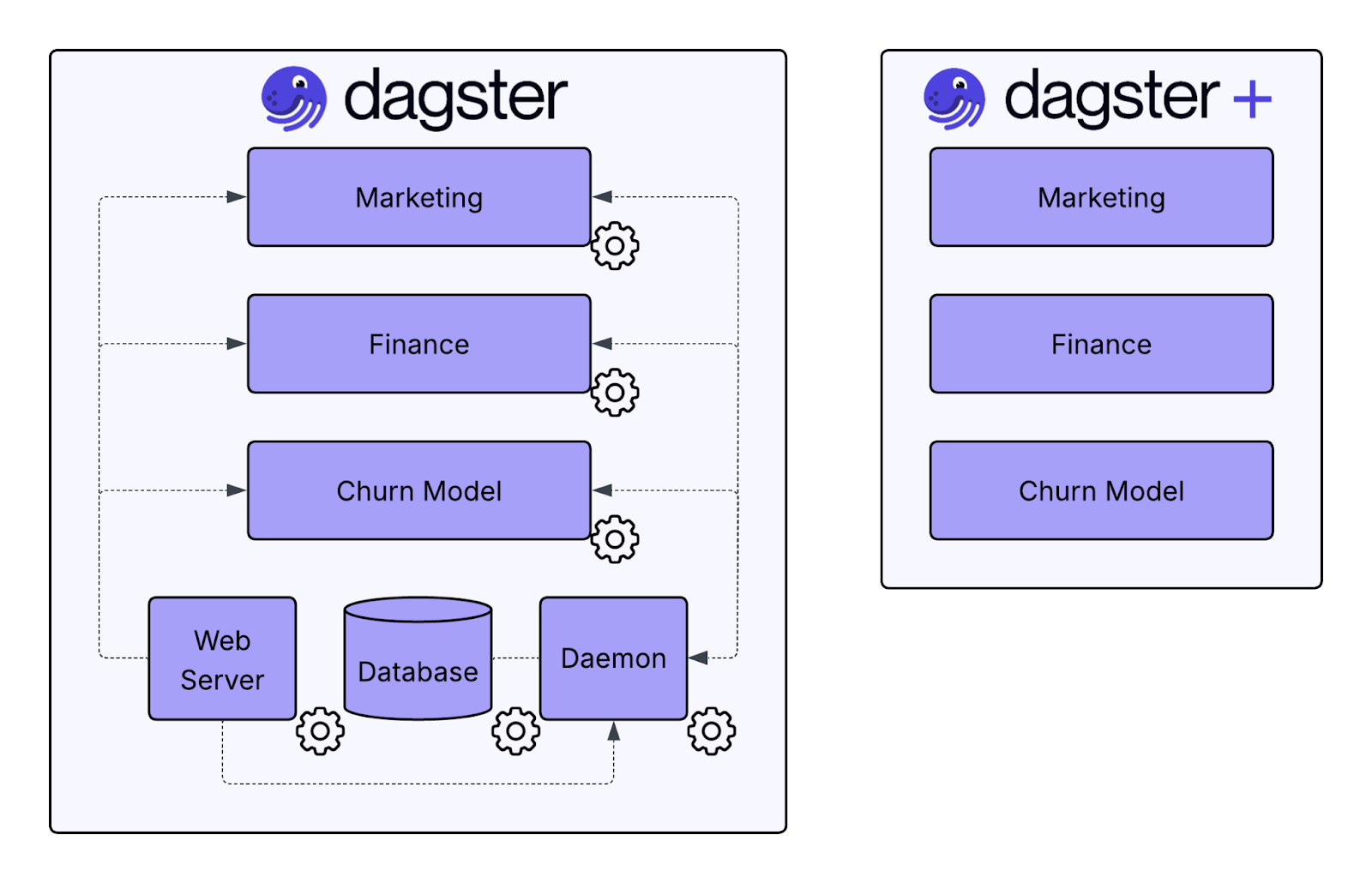
Moving to Dagster+ is not about outgrowing Dagster. It is about outgrowing the operational overhead that comes with running it yourself at scale. The tool is the same. The asset model, the Python APIs, and the sensor and schedule primitives all carry over. What changes is who handles the infrastructure, access control, environment management, and the observability layer.
At Dagster we think a lot about the problem of “Big Complexity”: the inevitable operational burden of scale that must be systematically managed so teams can stay focused on building, not maintaining. Dagster+ is our way to make these problems more manageable and allow teams to maintain momentum as they grow.
Infrastructure Management
Running Dagster OSS in production means owning the control plane, the webserver, the daemon, and the database that backs them. It means keeping up with security patches, managing backups, and being responsible if anything goes wrong.
For some teams, this overhead is manageable early on. But as pipelines become business critical, “manageable” is no longer enough. Reliability becomes the standard. The work compounds; running the control plane, managing SSL certificates, maintaining high availability, responding to incidents, and handling database migrations across Dagster versions.
Dagster+ handles all of that. You get a 99.9% uptime SLA, new deployments in clicks instead of Terraform plans, and automatic updates without migration risk.
For teams with regulatory requirements, being able to easily manage deployments across regions (including EU deployments) provides data isolation for GDPR compliance without standing up a separate control plane from scratch that would require a dedicated DevOps teams to maintain.
Role-Based Access Control
When it is just you and a co-founder, RBAC is overkill. You both have admin access to everything, and that works. The moment you bring in a second data team, a group of analysts, or stakeholders who should be able to view runs but not trigger them, the calculus changes.
Dagster+ includes fine-grained RBAC across the entire platform. You can grant view-only access to business stakeholders, developer-level access to data engineers, and admin privileges to the right owners, all without writing custom authorization logic or wrapping Dagster behind a proxy.
For larger organizations, Dagster+ also supports audit logs so you can see who did what and when, along with SSO integration for the providers your IT team already manages, including Okta, Azure Active Directory, and Ping Identity. And SCIM provisioning helps automate the creation, updating, and deprovisioning of user accounts across applications.
Environment Management
Most teams start with a single Dagster deployment. That is the right call in the beginning. You do not need dev, staging, and prod isolation until you have data products that support production workloads.
But data products do not behave like other applications. Many have side effects that are not always obvious. A job that writes to the wrong table or sends a notification to a real customer from a development environment can create much more work that needs to be undone than the initial feature.
Dagster+ makes environment isolation practical. You can run separate deployments for development, staging, and production with different credentials and infrastructure configurations without maintaining multiple control planes yourself. This allows you to build much more confidently as work moves through dedicated environments before it safely reaches production.
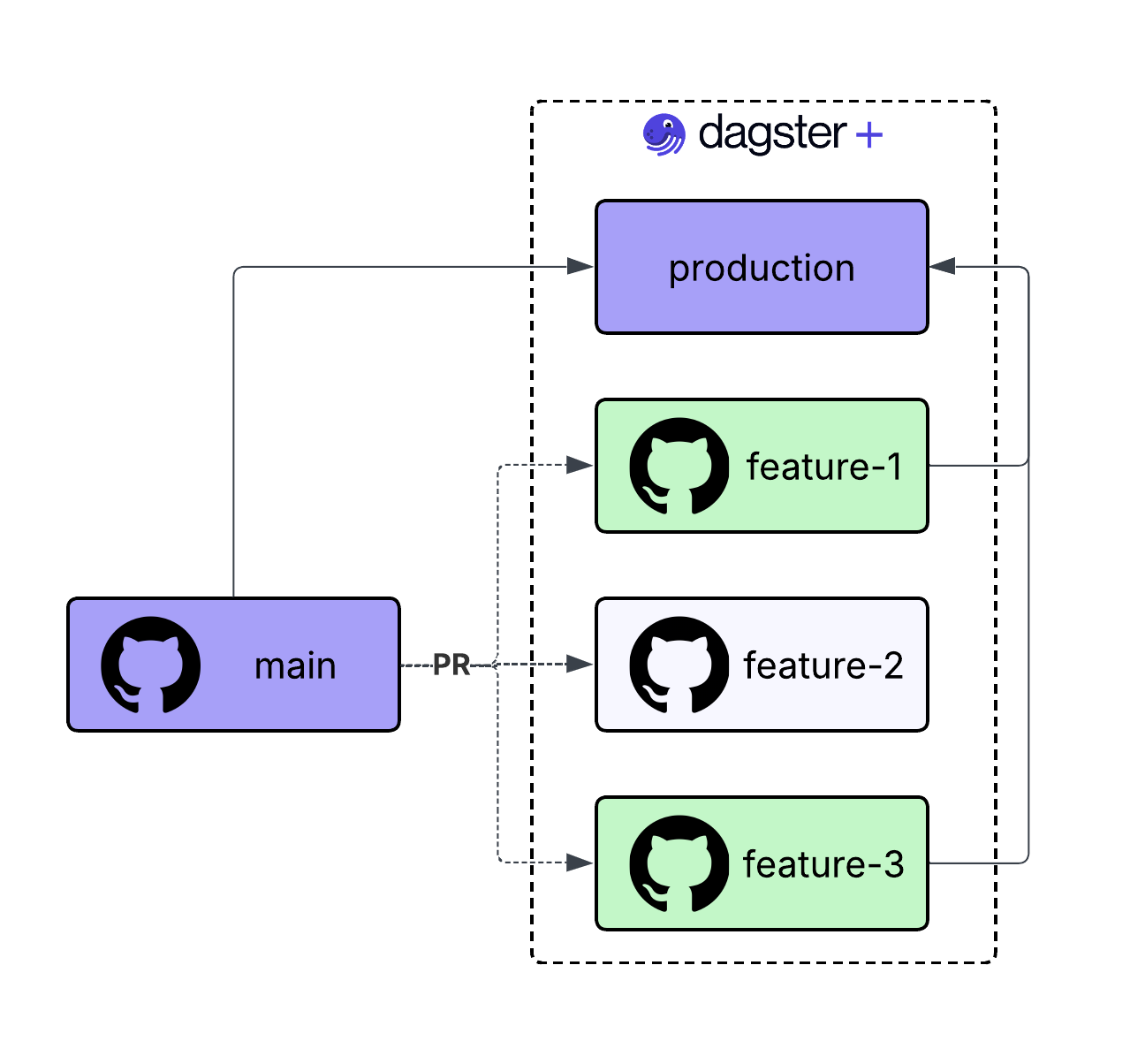
An even more compelling feature are branch deployments: ephemeral Dagster environments that spin up automatically when a pull request is opened and tear down when they are closed. This gives your CI pipeline a full, isolated environment for every PR, complete with its own asset graph and run history.
This becomes especially important as AI agents enter the picture. When an agent is generating pipeline code, branch deployments let it work in complete isolation, with a human reviewing the materialized results before anything merges to production.
Observability
Dagster OSS includes a certain level of alerting. But when data starts to become business critical, there is a much greater need for a single pane of glass over your assets and jobs.
Dagster+ gives you granular alert conditions, including data quality checks and asset freshness policies that trigger independently of job success or failure. You can route alerts where they will actually be seen, including Slack, Microsoft Teams, PagerDuty, and email.
Beyond alerting, Dagster+ includes a full asset catalog with column-level lineage, ownership tracking, and cross-project lineage. This is not just a technical feature. It solves a stakeholder problem. When an analyst asks, “Where does this metric come from?” or an ML team needs to understand what data feeds a model, they need something they can navigate. The catalog makes your assets discoverable to the people who depend on them, not just the engineers who built them.
OSS vs Dagster+
The difference is not what you can build. It is what you have to maintain.
The Same Foundation, Enterprise-Ready
Dagster+ extends Dagster OSS. It does not replace it. The asset model you have built, the Python code you have written, and the mental model your team has developed all carry over. What you gain is the operational layer that becomes expensive to maintain on your own as the platform matures.
If your team is spending meaningful engineering time on infrastructure, access management, or environment wrangling instead of building pipelines, it is worth exploring what the managed experience looks like. If you are starting a new project and want the full experience from day one, Dagster+ provides it without the unnecessary ramp.





.png)
.jpg)