August 10, 2021 • 8 minute read • ![]()
Community Memo: Moving Dagster's Core APIs Towards 1.0



- Name
- Sandy Ryza
- Handle
- @s_ryz
As data practitioners increasingly depend on Dagster as a critical piece of their platforms, we believe it’s important to commit to a stable set of APIs that they can expect to remain the same for a very long time.
Before making that commitment to stability, we wanted to make sure we could confidently say that our APIs are as intuitive and simple as they can be. So we asked ourselves “Which of our current APIs will stand the test of time, and what have we heard from users about what will not? Where do we get the most critical feedback? Which parts of our APIs inspire the most confusion?”
This post will cover what we’ve heard and observed, and it will describe the new set of Dagster core APIs that we’ve developed to take the place of some of the more confusing parts of Dagster’s existing APIs. At a high level, we’re planning to consolidate many of Dagster’s core concepts into a few, simpler concepts.

These changes are experimental in our latest release, 0.12.0. We think they’re a huge step forward for the intuitiveness of Dagster’s APIs, and we’d love for you to try them out and tell us what you think.
What we’ve heard
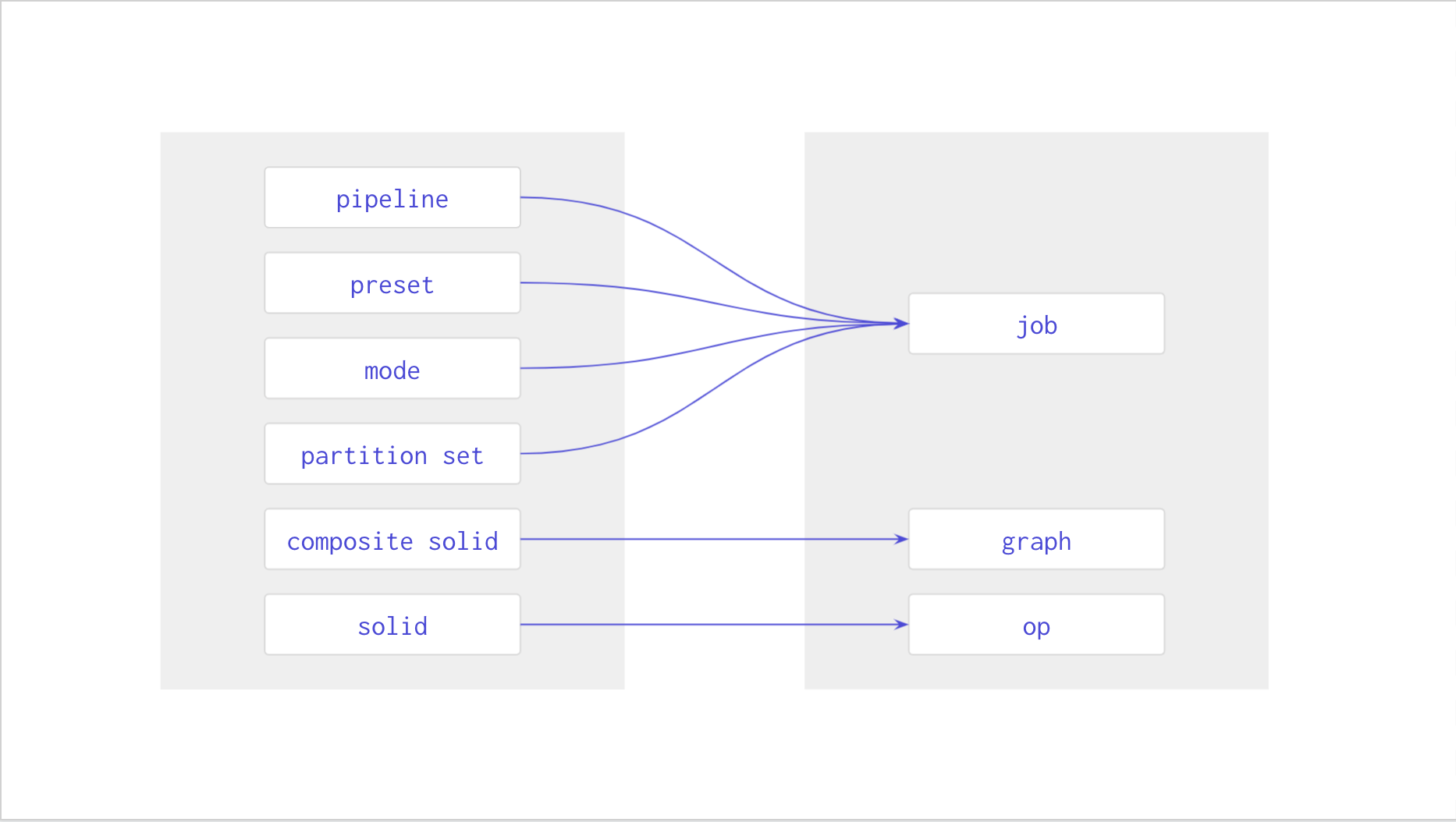
What’s the difference between a preset, a partition set, and a mode?
Users often tell us that they grasp the basics of constructing a pipeline very quickly, but that it takes them a while to understand the array of concepts that Dagster provides for dealing with more complex parameterizations of their pipelines: modes, presets, and partition sets. Part of what’s difficult here is that these concepts play similar roles. Modes and presets both help model different environments (e.g. production and staging). Presets and partition sets both provide default configuration to a pipeline.
Why can’t I nest a pipeline in a pipeline?
Pipelines and composite solids are both ways of defining dependency graphs of solids. Solids and composite solids, while named similarly, work very differently (the code inside a solid runs when the pipeline runs, but the code inside a composite solid runs when the pipeline is being defined).
How do I unit-test my pipeline?
One of the core goals of Dagster’s resource system is to make it easy to test pipelines. The resource system essentially allows solids and pipelines to define pluggable extension points where different resources can be provided, enabling the same pipeline to be executed in different environments. However, in the current implementation, all resources that a pipeline can be executed with need to be supplied to the pipeline at the place where the pipeline is defined. This works well for integration tests, but means it can be very difficult to actually take advantage of the resource system in pipeline unit tests - there’s no straightforward way to create an ad-hoc resource inside a unit test and execute a pipeline with it.
What’s my “dev” mode doing here in prod?
Another point of awkwardness is that Dagster instances typically include modes, presets, and partition sets that cannot or should not be launched on them. For example, it’s typical to define a pipeline with production and development modes, to include that pipeline on your production instance, and then to come across the development mode when viewing your pipeline in production. The pipelines aren’t meant to be executed in their development modes from the production deployment, but, because the mode is attached to the pipeline, it shows up there. This is distracting and confusing for anyone trying to operate the pipeline in production.
What’s a “solid?”
Last, but not least, one of the most persistent pieces of critical feedback we’ve gotten on Dagster’s APIs has been the name of its core abstraction - “solid”. People who have spent a lot of time with the framework mostly get used to it, but new users almost unanimously find it difficult to understand what the name “solid” has to do with executing graphs of data computations.
The changes
With these difficulties in mind, we’re planning to make a few big changes to Dagster’s APIs.
Solid → Op
We are planning to rip the band-aid off and replace the name “solid” with the name “op”. “Op” is short for “operation” - the name is a much better fit than solid for a concept that is a functional unit of computation. We chose “op” over a name like “task”, because we wanted to capture the connotation of a logical operation, not a physical execution. Ops have inputs and outputs, and they may be parameterized to execute in different environments. In future versions of Dagster, we’re interested in offering the capability to fuse multiple ops into a single step, which would allow sub-graphs to pass data in memory even when the overall graph is executing in a distributed manner.
We will maintain backwards compatibility for a year at the very least. We don’t take this change lightly, because we know that it will mean changing a lot of code, but, for the long run, we think it’s important for making the project as accessible and successful as possible.
Along with op, we’ve introduced more concise APIs for defining Dagster Types and metadata on inputs and outputs.
from dagster import In, Out, op
@op(ins={"arg1": In(metadata={"a": "b"})}, out=Out(metadata={"c": "d"}))
def do_something(arg1: str) -> int:
return int(arg1)
Graph and Job
We’re planning to replace pipelines, modes, presets, composite solids, and partition sets with a pair of new abstractions: graph and job.
Pipelines encapsulate a large number of independent concepts. In addition to defining the logical structure of dependencies, a pipeline must also enumerate all of possible modes it could be run in, with each mode in turn enumerating all of the required resources, potentially paired with multiple presets per mode.

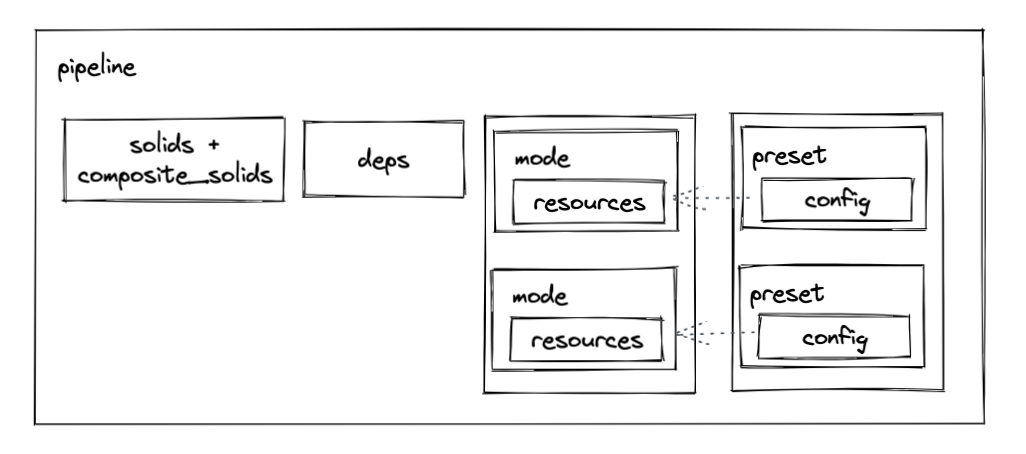
In contrast, the new APIs allow the dependency structure (now called a "graph") to be separated from the definition of the resources that it might be used with. "Jobs" are executable specializations of graphs. A job binds a graph to a set of resources and default configuration or a set of partitions. Each schedule or sensor targets a job. You can create multiple jobs from the same graph, e.g. a dev job and a prod job. If, previously, you had a pipeline with three modes, you’d likely now have three jobs that all reference the same graph.

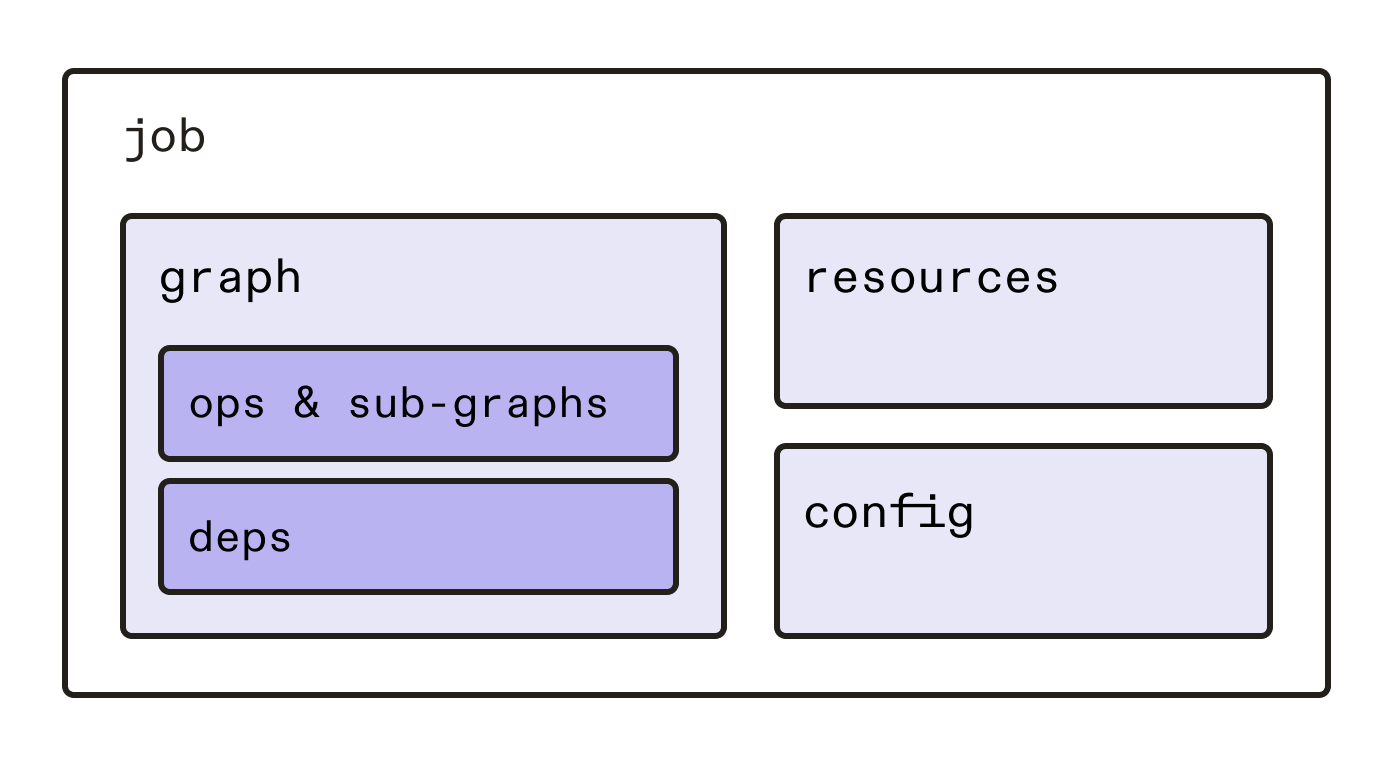
Dagster is built around the observation that any data DAG typically contains a logical core of transformation (the graph), which is reusable across a set of environments, but then also that different environments need to specialize it by plugging in particular configuration or clients of particular services. The switch to graphs and jobs was based off this along with a distillation of the observations discussed in the previous section:
- Even though the same graph is reusable across multiple environments, most development and operational workflows focus on a single environment. When you’re trying to understand what happened in production, you rarely care about the test configuration of your graph or test runs of your graph.
- At the site where you define a graph, you aren’t necessarily in a position to define all the ways it will ever be parameterized. You often want to supply resources or default config elsewhere (e.g. in unit tests).
How this helps
This reorganization of concepts offers a number of advantages:
Avoid deploying local test jobs to prod
Repositories will now be able to selectively include jobs from a graph. This means that your production instance doesn’t need to be cluttered with the dev modes of all your pipelines. E.g. you can provide a production repo with production jobs and a dev repo with dev jobs. Then, in your production workspace.yaml, you can reference the production repo, and, in your dev workspace.yaml, you can reference the dev repo:
from dagster import graph, repository
@graph
def do_it_all():
do_something()
@repository
def prod_repo():
return [
do_it_all.to_job(
resource_defs={"external_service": prod_external_service}
)
]
@repository
def dev_repo():
return [
do_it_all.to_job(
resource_defs={"external_service": dev_external_service}
)
]
Mock resources inside tests
You can now execute a graph with resources you construct inside a unit test. Because it’s no longer required to define all possible resource parameterizations at the pipeline definition site, you can now construct resources inside your test test and execute the pipeline with them.
Part of the advantage here is requiring less boilerplate. The other part is enabling usages that were nearly impossible in the old APIs. Now you can have 10 different tests each construct their own resource, rather than anticipating every test where the pipeline is defined.
from dagster import graph
@graph
def do_it_all():
...
def test_do_it_all():
do_it_all.execute_in_process(
resources={"external_service": MagicMock()}
)
Point with object references, not strings
Schedules and sensors now target jobs using Python object references, not strings. This means you can discover errors earlier, because linters can tell you if your schedule points to a pipeline that doesn’t exist. It also makes the code briefer.
from dagster import ScheduleDefinition
do_it_all_schedule = ScheduleDefinition(
cron_schedule="0 0 * * *", job=do_it_all
)
Nest graphs inside graphs
Graphs can be nested inside other graphs. This didn’t make sense with pipelines, because nesting a pipeline with multiple modes inside another pipeline has all sorts of wacky implications. Taking modes off of pipelines allows Dagster to provide a single abstraction for both the entry point and composition.
from dagster import graph
@graph
def my_inner_graph_1():
...
@graph
def my_inner_graph_2():
...
@graph
def my_outer_graph():
my_inner_graph_2(my_inner_graph_1())
In Dagit, consolidate on jobs
With the previous APIs, pipelines have a one-to-many relationship with modes and thus a one-to-many relationship with schedules and sensors. To faithfully capture this one-to-many relationship, the left navigation pane essentially needed to display everything twice:
With the new APIs, each job typically has at most a single schedule or sensor. This allows for a simpler left navigation pane, which just shows the list of jobs. The page for a job renders information about its associated schedule or sensor.
| Left nav before | Left nav now |
|---|---|

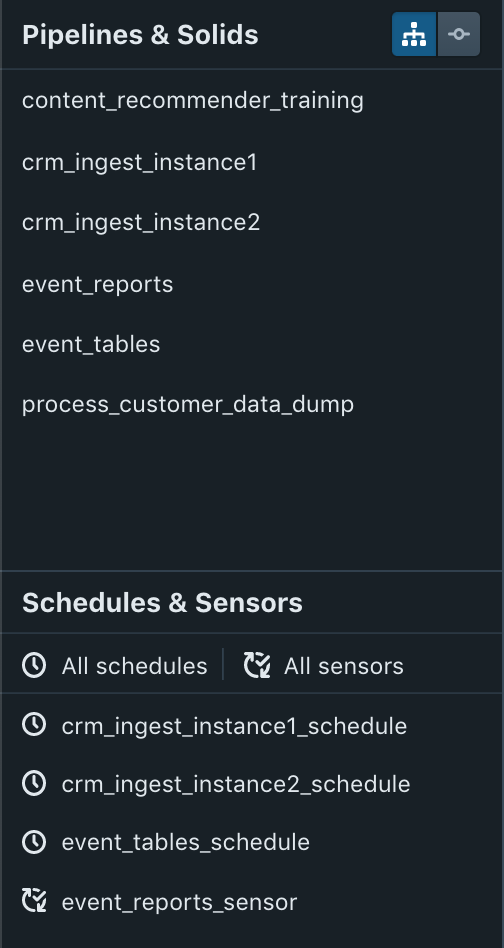

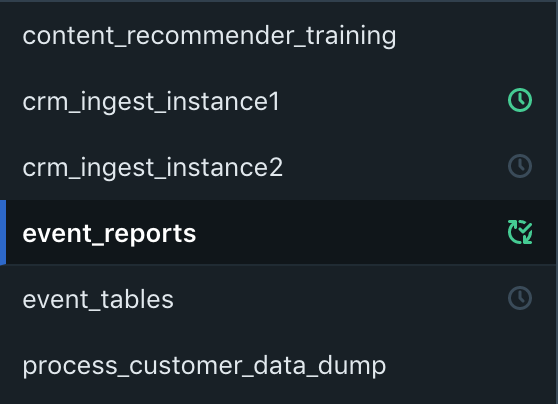
The page for a job renders information about its associated schedule or sensor.


Try it out and tell us what you think!
We think these new APIs are a huge step forward for the approachability and ergonomics of Dagster’s APIs, but before we switch over to them, it’s important for us to hear how they work for you. We would love for you to try them out and give us your honest feedback. None of this is yet set in stone, and, by telling us what you think in the next months or two, you can have a lot of influence over what the final product looks like.
Converting a pipeline or two to the new APIs does not require converting all your pipelines. For details on how to try out these changes, take a look at the graph/job/op migration guide. It contains detailed comparisons of the of the new and old APIs, as well as instructions on how to toggle Dagit to take a graph/job/op view.


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


Community Memo: Pythonic Config and Resources


- Name
- Nick Schrock
- Handle
- @schrockn

- Name
- Ben Pankow
- Handle
