November 5, 2020 • 4 minute read • ![]()
Good Data at Good Eggs: Data Observability with the Asset Catalog



- Name
- David Wallace
- Handle
- @davidjwallace
This is the third in a series of posts about putting Dagster into production at Good Eggs. Read the introduction and part one to learn more about our experience transforming our data platform with Dagster.
Though Dagster isn’t a specialized data observability solution, one thing we found attractive about the platform is that it integrates support for the most basic and most important kind of observability.
Why does observability matter? Well, if your data platform is anything like ours, a bunch of different tools sit between your raw data and the business outputs that really matter. You might use a tool like Stitch to ingest data from external sources, tools like dbt and Spark to transform, enrich, and reshape it in your data warehouse, and a tool like Mode Analytics to display meaningful aggregates to drive your decisions.
Clients of the data platform need to be able to answer their questions on a self-service basis.
What happens when a business user notices that a report looks a little out of date?
Debugging several layers of systems like this can be difficult — and historically, at Good Eggs, very manual. Business users would notice that a report looked a little stale. Analysts would have to come to the Platform Team to ask us to investigate. We would have to look at logs produced by and stored in several different systems to try to isolate the issue.
What about a plot or a chart generated by a Jupyter notebook? How easy is it to track down the computation that produced it (so you can debug, rerun, or backfill)?
What if an analyst notices that a dbt model is starting to feel a little sluggish? How easy is it for them to inspect the trend of its execution time?
Every organization that works with data faces questions like these. Routing them all through the Platform Team just isn’t sustainable. Clients of the data platform need to be able to answer their questions on a self-service basis.
Self-service observability
Although things like tables in a data warehouse, Jupyter notebook figures, and Mode Analytics reports are semantically very different, we can think of them all as assets produced by the computations we do in our pipelines. In fact, one way to think about a data application is that the assets it produces are the interface to the system.
Since Dagster is responsible for orchestrating the production of these assets anyway, it makes a lot of sense for it to put a common index on those assets. So Dagster includes a built-in asset catalog, and Dagster solids can yield specialized structured metadata to indicate they have produced assets that should be placed in the catalog.
This means that every time an asset is created, we can link it back to the computation that produced it. We can track the history of an asset over time, as input data and the logic of computations change. We can watch for trends. And we can explore a catalog of all the assets that our pipelines produce.
For example, many of our solids invoke dbt to materialize tables in our Snowflake data warehouse. Every time we successfully run a dbt model, we yield an AssetMaterialization to automatically record metadata about the table in Dagster’s asset catalog.
(We’ve actually contributed the dagster-dbt integration back to the core open source project — check out the blog post for more details — so you don't have to worry about writing this code yourself, but this is roughly how it works under the hood.).
def generate_materialization(context, node_result) -> Iterator[AssetMaterialization]:
...
entries = [
EventMetadataEntry.json(data=node_result.node, label="Node"),
EventMetadataEntry.text(text=node_result.status, label="Status"),
EventMetadataEntry.float(
value=node_result.execution_time, label="Execution Time"
),
EventMetadataEntry.text(text=node_result.node["database"], label="Database”),
EventMetadataEntry.text(
text=node_timing.completed_at.isoformat(timespec="seconds"),
label="Execution Completed At",
),
...,
]
yield AssetMaterialization(
description="A materialized node within the dbt graph.",
metadata_entries=entries,
asset_key=node_result.node["unique_id"],
)
This surfaces details about the model run in the Dagster UI. Now, our analysts can use a single portal to look up the history of their tables themselves, without the platform team getting involved.

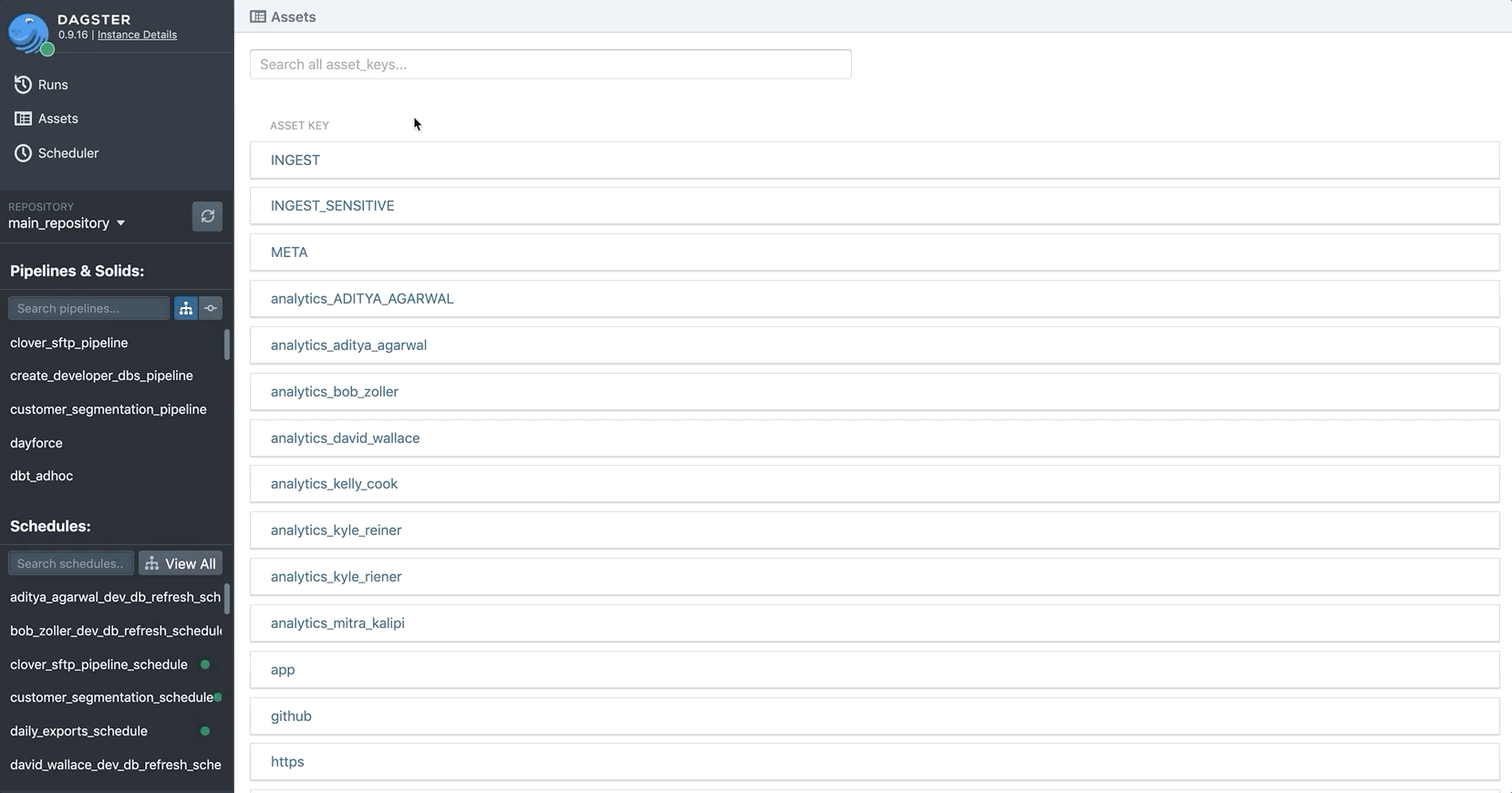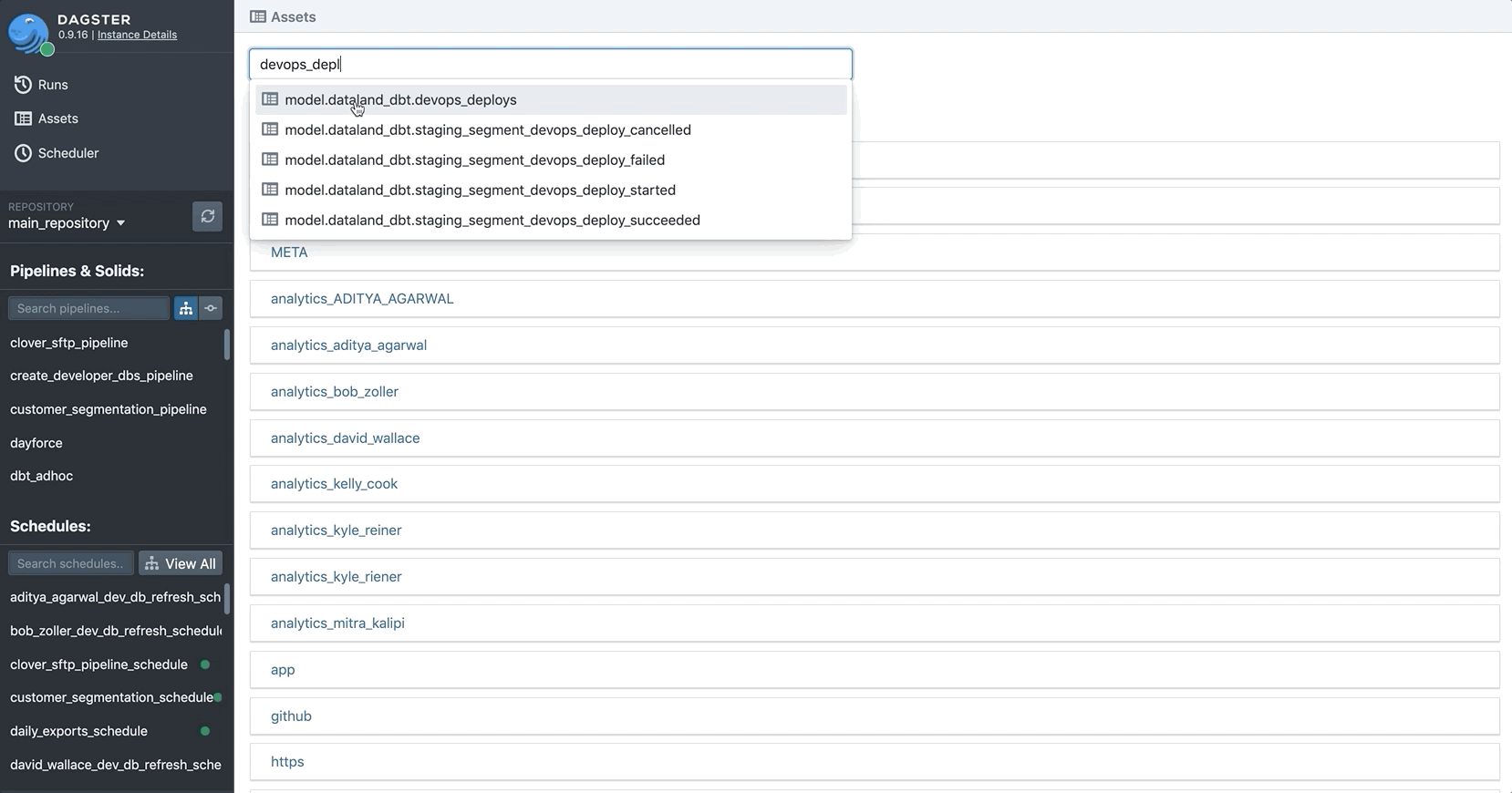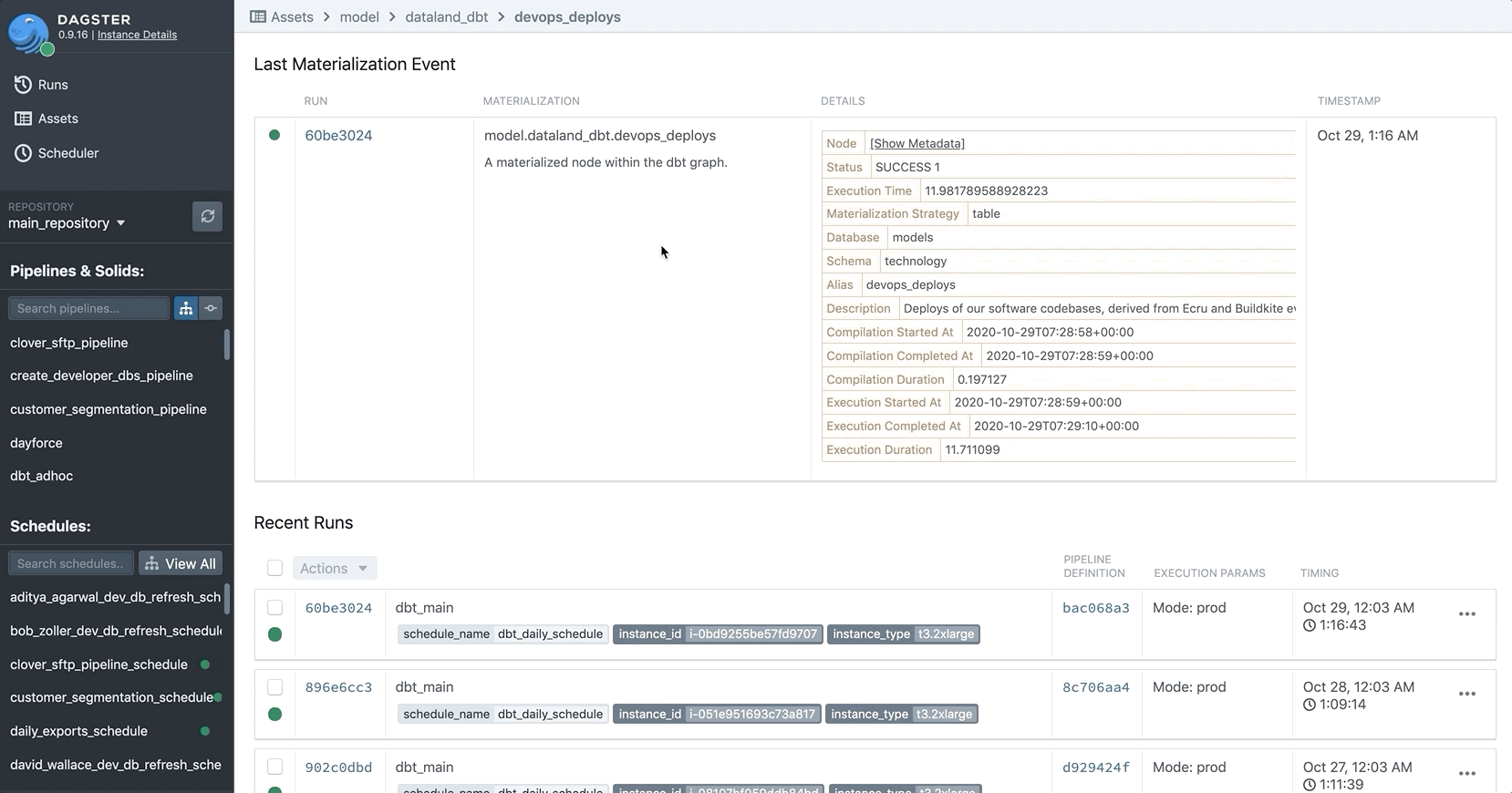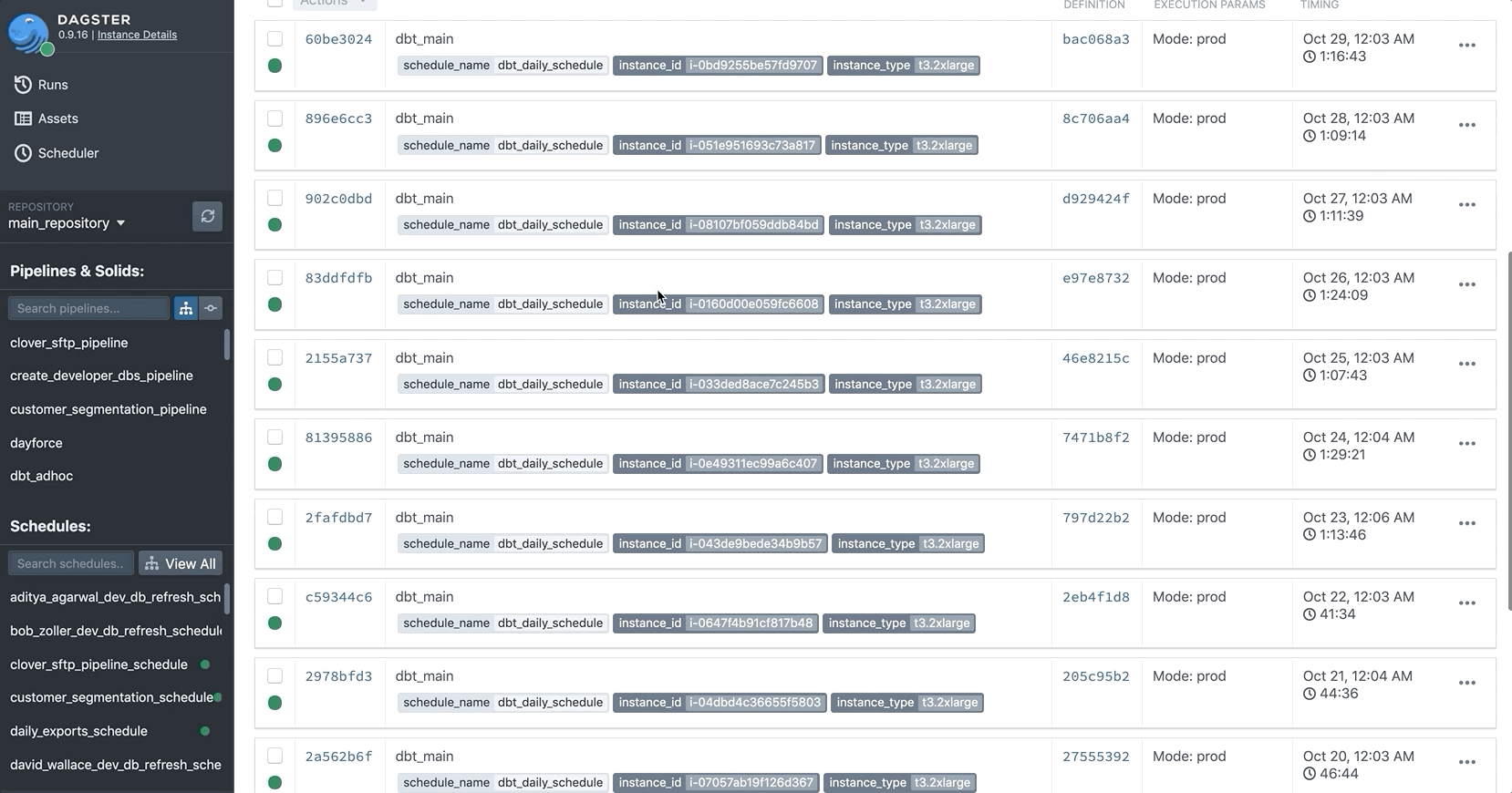
Representing asset creation in a structured way sets us up for a lot of future wins. For example, once asset metadata is recorded, it can be viewed longitudinally. For example, when we yield a float value, Dagster automatically renders a longitudinal chart as part of the asset catalog. Here, we use that capability to track the execution time of dbt models and find developing bottlenecks before they become problems.

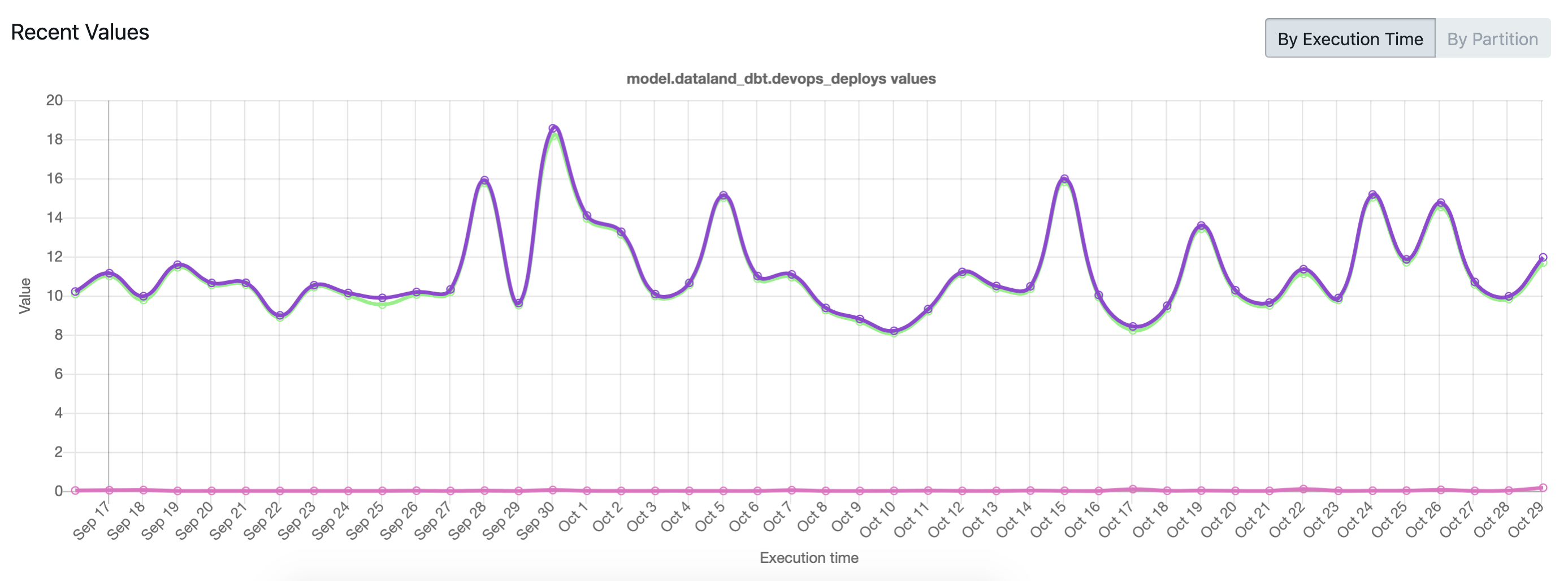
While there are other ways to track this sort of thing — for instance, by logging the execution time to a specialized metrics system — we get these charts for free, just from yielding metadata about the execution time as a float. Since we don’t necessarily know in advance which of our metadata items will be important to track in the future, this saves us a bunch of manual work.
All meaningful side-effects are assets
The idea of tracking changes to database tables in an asset catalog is probably familiar to most data practitioners. But the idea of asset materialization can be extended to cover any meaningful side-effect of your computation whose lineage you’d like to track.
What we’re aiming for with Dagster is a completely horizontal view of our data assets.
For example, we’ve found that when important plots and figures are generated by Jupyter notebooks, it’s important to proactively surface them to users rather than wait for someone to remember to check the notebook output. For us, that means that figures should get sent to Slack channels as soon as they’re created.
These plots posted to Slack can also be understood as assets created by our computation. And so we’ve written our Slack solid to yield an AssetMaterialization every time it posts a message or a file. We even include links back to Slack as metadata on our materializations, so that analysts can go straight from the asset catalog to the artifact that was surfaced in our Slack.

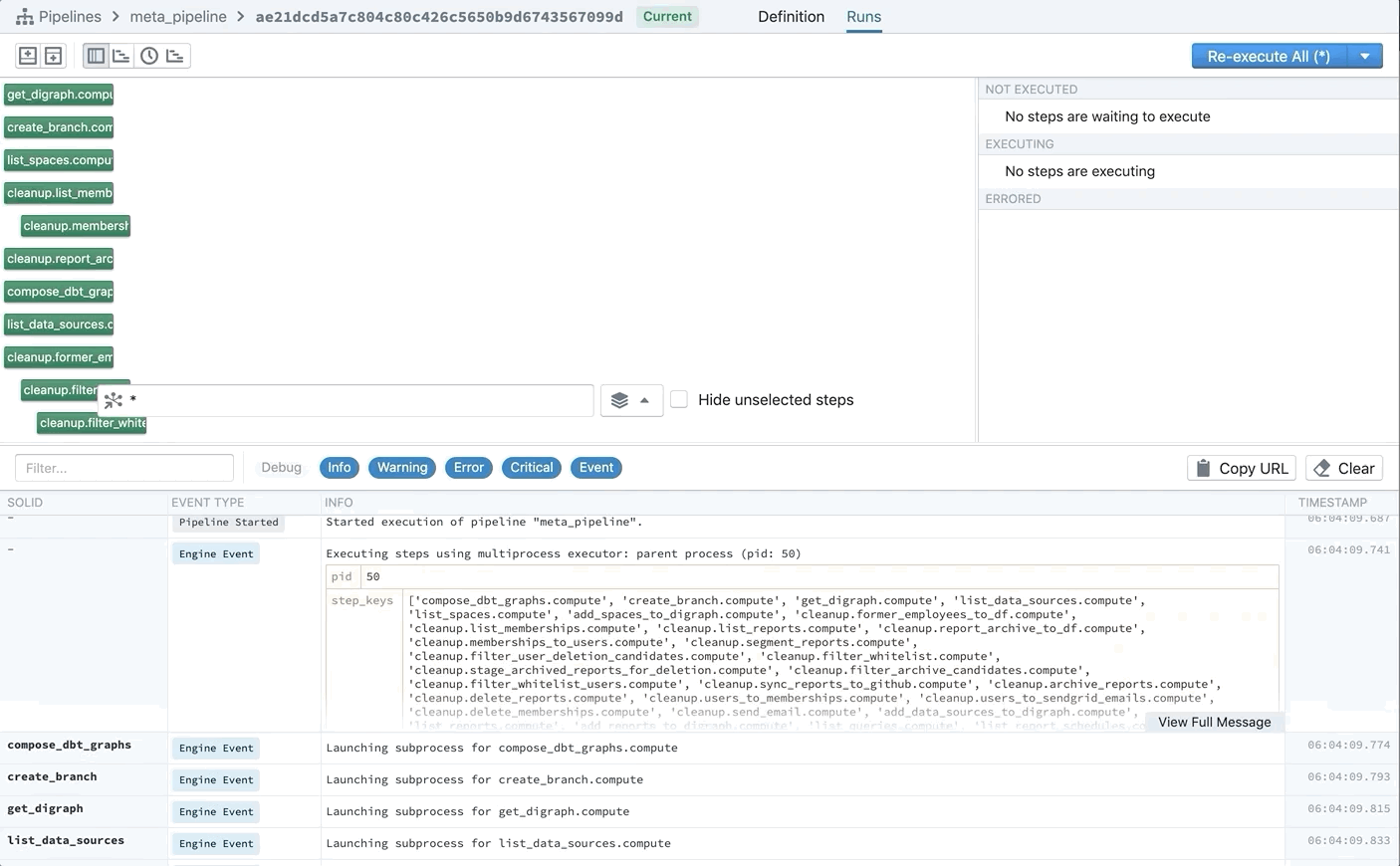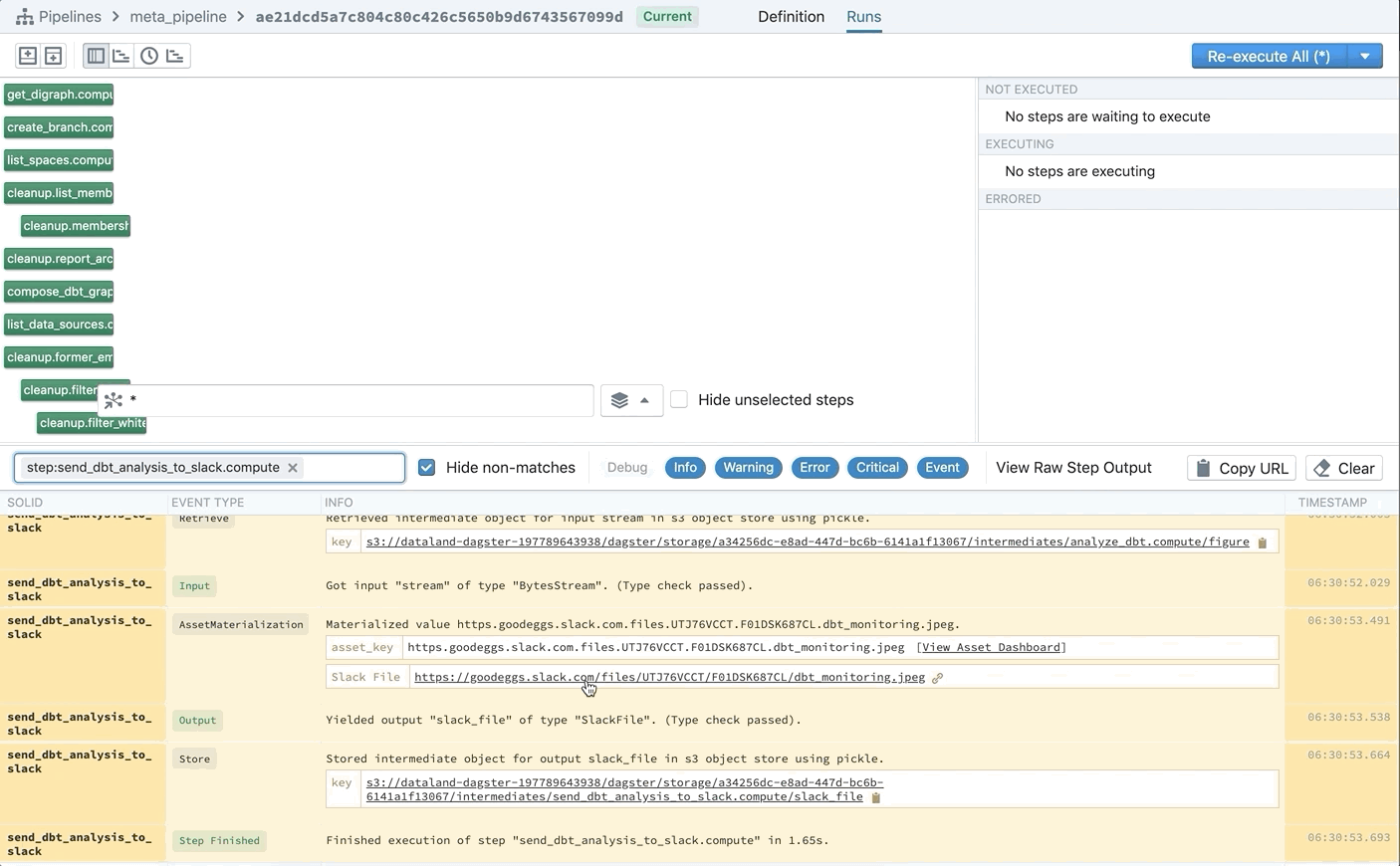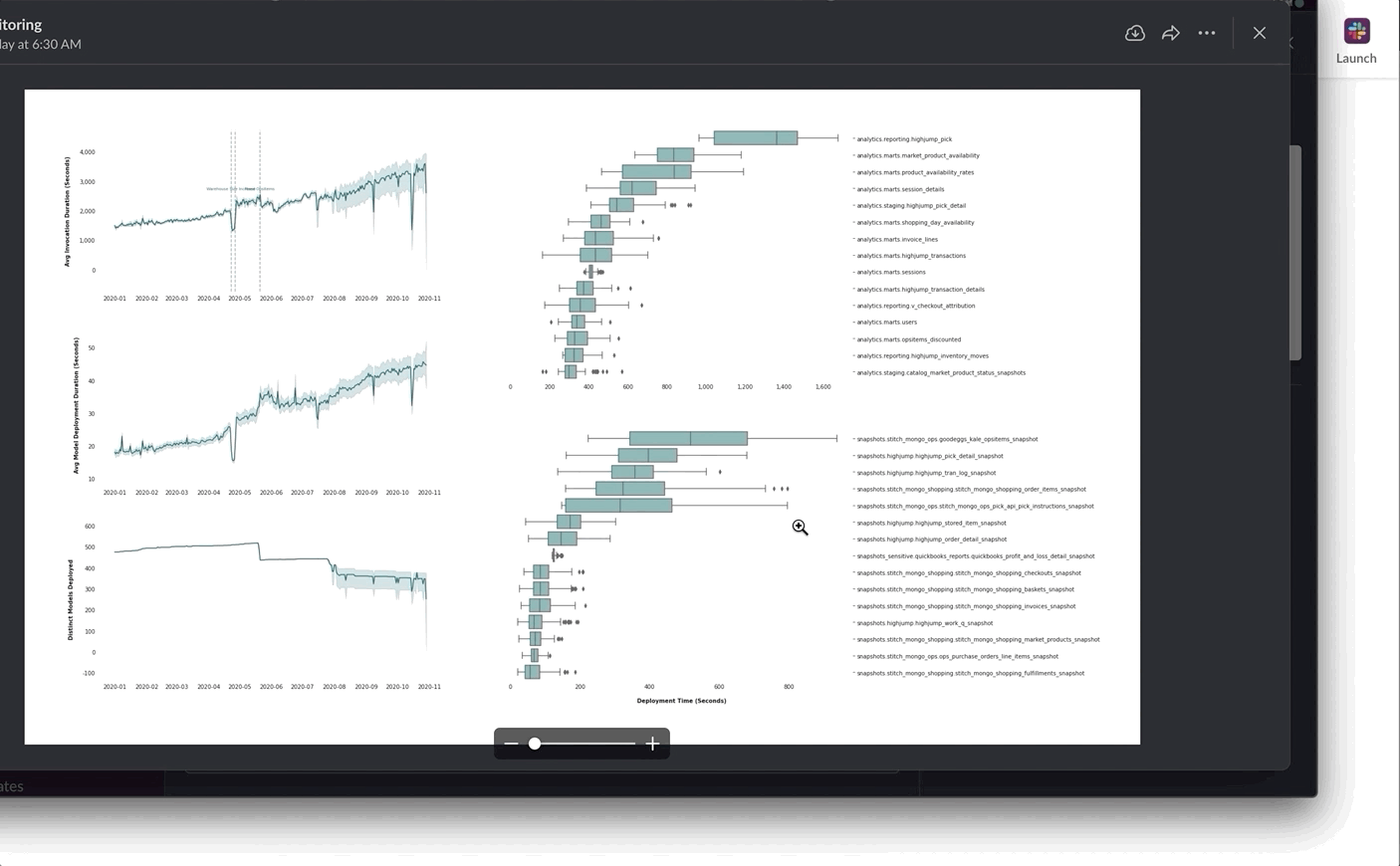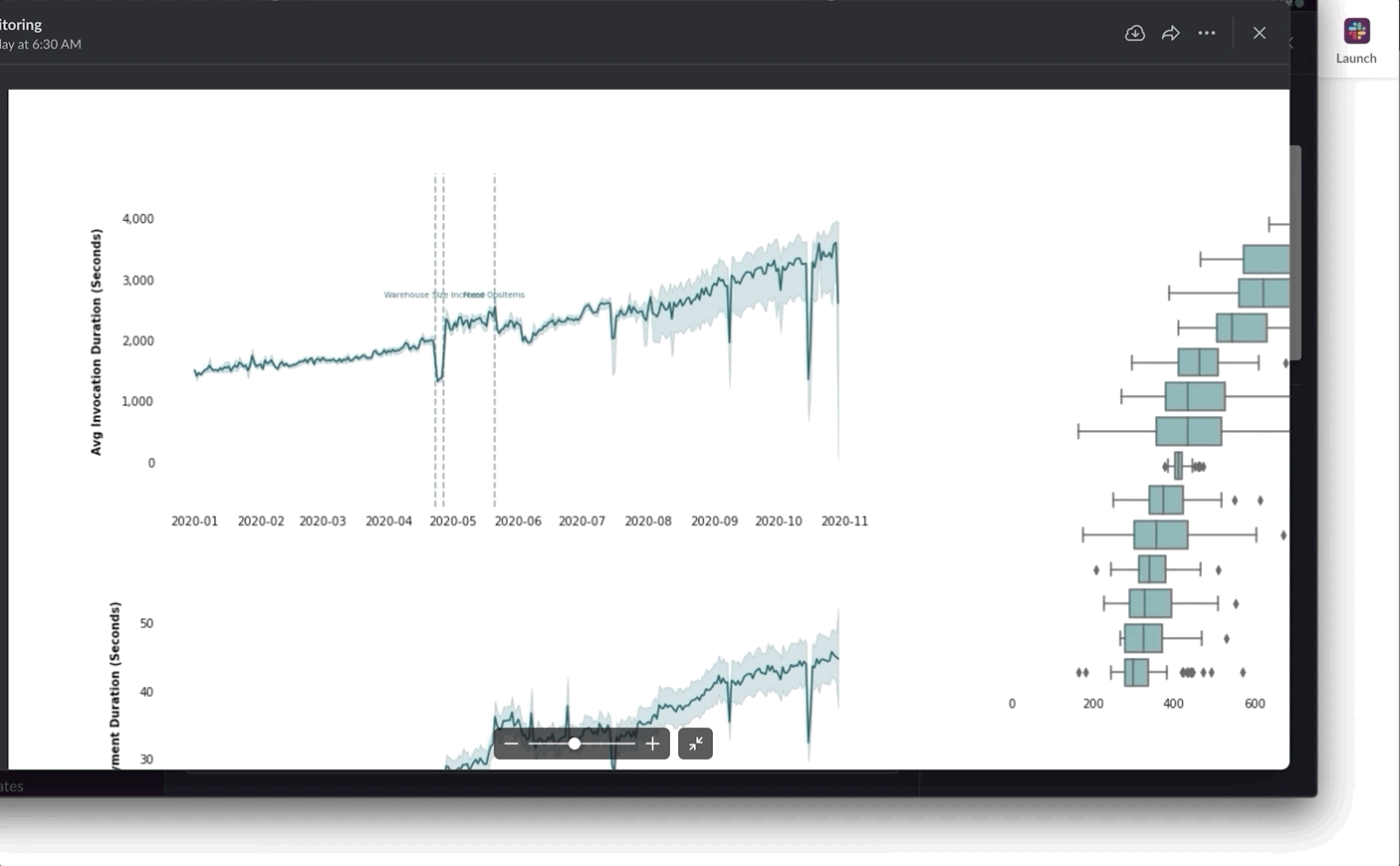
Now it’s easy to answer questions like: Where did this image come from? What plot did this code render?
Representing the assets created by our computations in a structured way in the asset catalog helps to close the loop on the analytics workflow. Analysts can write and test their models in dbt, then deploy and operate them alongside other tools with Dagster, and track their results in the Dagster asset catalog. Users who aren’t on the Platform Team have observability for the products of their computations, and the lineage of our data assets is clear.
What we’re aiming for with Dagster is a completely horizontal view of our data assets. Our analysts will be able to look up when a raw data ingest from Stitch occurred, when a dbt model ran, or when a plot was generated by a Jupyter notebook and posted in Slack, through a single portal — a single “pane of glass” onto all the assets produced by our data platform.
We hope you’ve enjoyed reading about our experience with Dagster so far. Check out the next post in the series to learn about how we're using Dagster to manage the platform.


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


BenchSci: A Leap Forward with Dagster


- Name
- TéJaun RiChard
- Handle
- @tejaun

Abstracting Pipelines for Analysts with a YAML DSL

- Name
- Fraser Marlow
- Handle
- @frasermarlow

Catalyst Cooperative: Liberating Public Utility Data with Dagster
- Name
- Fraser Marlow
- Handle
- @frasermarlow