March 1, 2022 • 2 minute read • ![]()
Dagster 0.14.0: Table Schema API + Pandera Integration



- Name
- Sean Mackesey
- Handle
Data assets are opaque without metadata. Asset consumers need answers to questions like: What does this table represent? What are the columns? What are their formats? When was it last updated? Are there expectations for what the content should look like? Does it meet those expectations?
Traditional orchestrators like Airflow lack a natural place to store this metadata. This is because assets are not first-class citizens in the task-based orchestrator data model. Any available information about assets tends to be refracted through task-centric feedback formats, e.g. stdout/stderr logs. Consequently, orchestrators do not effectively support users in managing the potentially immense output of assets and "data exhaust" from a modern data platform.
Dedicated metadata catalogs like Amundsen and Datahub have been developed to meet this need. These are powerful tools, but they have a limitation opposite to that of traditional orchestrators-- their data model has no place for code. Finding the logic that generated an asset is likely to be a complex task with organization-specific idiosyncrasies.
This schism between code and data is a foundational problem of data engineering. It exists because of the different demands of code-first (orchestrator) and data-first (catalog) perspectives. The field has thus far favored tools that limit their scope to one of these perspectives. This made sense in the complex and rapidly evolving data engineering problem space. However, this fragmentation has made maintenance of data quality difficult. It is hard to identify data problems at the orchestrator level because the view of the generated assets is hazy. And it is hard to address data problems at the catalog level because there is no clear link to the code that defines the cataloged assets.
We think there is room for improvement. While an orchestrator shouldn't take on the responsibilities of a full-featured catalog, it can help bridge the code-data gap by carving out a place in its data model for richly annotated assets. To get the ball rolling, 0.14.0 includes a stack of three new features: an API for attaching metadata to assets and Dagster Types, a new Table Schema API that allows expression of tabular schemas as metadata, and an integration (built on the Table Schema API) with the Python dataframe validation library Pandera.
Metadata on Assets and Dagster Types
Dagster 0.14.0 introduces the ability to put user-defined typed Metadata on Assets and Dagster Types. This metadata is rendered in Dagit in both the sidebar of the graph explorer view and in the asset details view.
Table Schema API
Dagster 0.14.0 includes an experimental new Table Schema API for expressing the structure of tabular data assets. TableSchema objects can be attached to Dagster Types, Assets, and Events as Metadata Entries. They are rendered in Dagit alongside the views for these entities:

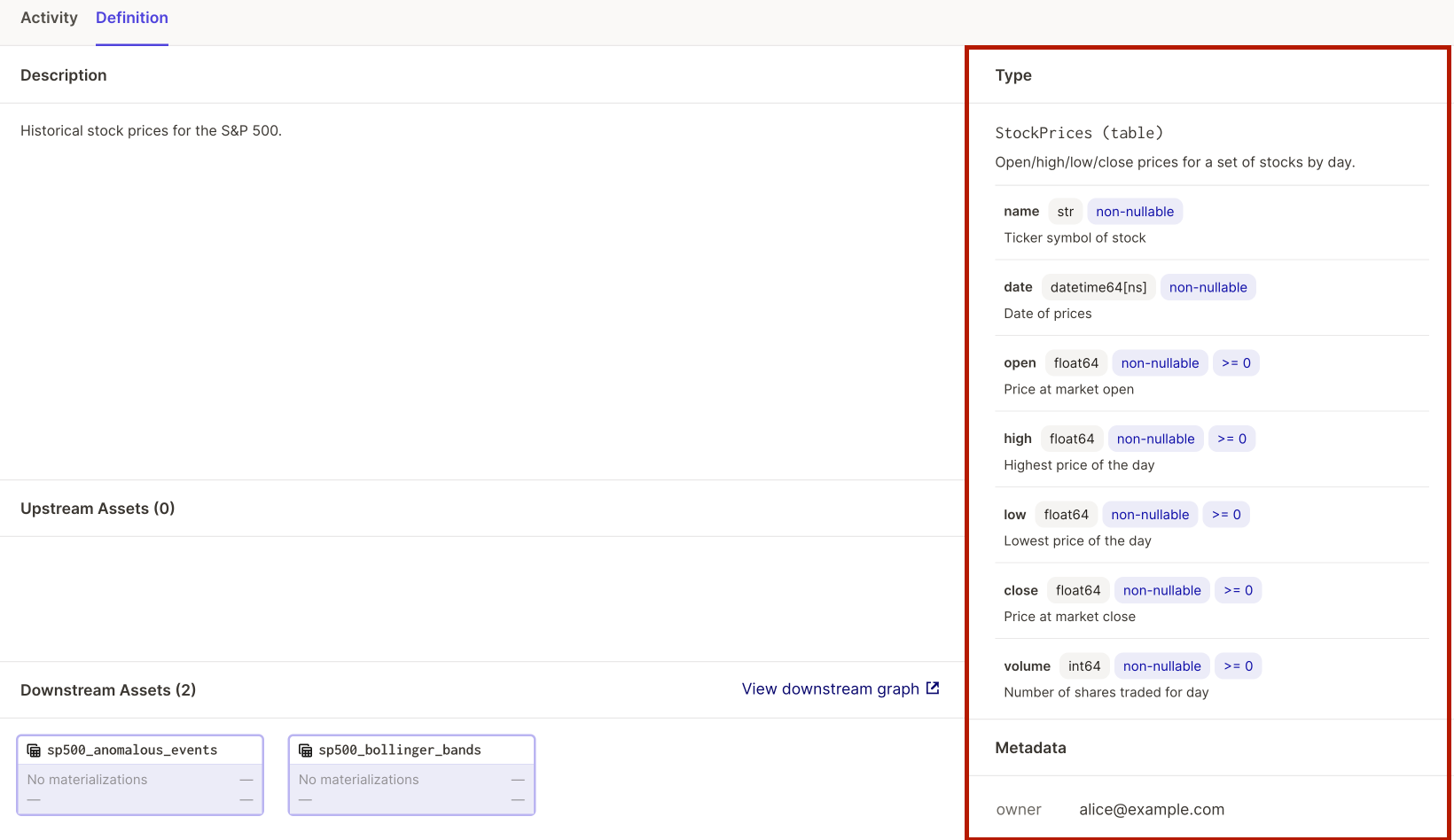
Table schemas offer immediate benefits for observability of tabular assets:
- Meaning. The schema may contain arbitrary column descriptions and string representations of single (e.g. col a >= 0) or multi-column (e.g. col a > col b) constraints.
- Shape. For pipelines that transform tabular data, you can see changes in the structure of the data in Dagit’s op or asset graph views.
- Integrity. Schemas may be attached both to materialization events and Dagster types, allowing comparison between an asset’s in-process schema (expressed on its type) and the storage schemas of any materializations.
Nobody wants to learn a new format for specifying column schemas, and nobody wants to specify the same schema in two different places. We expect users will typically instead want to generate Dagster TableSchemas from an existing source of truth. While the Table Schema API makes it easy to write an adapter for arbitrary source formats, we're providing out-of-the-box integrations with some popular tools:
- When you add column documentation and data types in a
dbtschema.yml and load your dbt project as software-defined assets, that column metadata will show up as a DagsterTableSchema. - We'll soon provide a utility for building
TableSchemasout of SparkStructTypes. - 0.14.0 includes a new integration library with the Python dataframe validation library
Pandera.
Pandera Integration
Pandera is a library that implements data validation for Pandas-like dataframes. We say “pandas-like” because Pandera supports both Pandas and several Pandas-inspired dataframe implementations in other libraries, e.g. Dask and Koalas.
There are two core Pandera classes: DataFrameSchema and SchemaModel. Both classes are used to express a dataframe schema— they are just alternative APIs. A DataFrameSchema/SchemaModel captures arbitrary Python-based single or multi-column “checks” of a dataframe. It can also hold textual descriptions of columns and constraints.
class StockPrices(pa.SchemaModel):
"""Open/high/low/close prices for a set of stocks by day."""
name: Series[str] = pa.Field(description="Ticker symbol of stock")
date: Series[pd.Timestamp] = pa.Field(description="Date of prices")
open: Series[float] = pa.Field(ge=0, description="Price at market open")
high: Series[float] = pa.Field(ge=0, description="Highest price of the day")
low: Series[float] = pa.Field(ge=0, description="Lowest price of the day")
close: Series[float] = pa.Field(ge=0, description="Price at market close")
volume: Series[int] = pa.Field(ge=0, description="Number of shares traded for day")
dagster-pandera exposes a Dagster Type factory function (pandera_schema_to_dagster_type) that takes in a Pandera DataFrameSchema or SchemaModel and outputs a DagsterType. Under the hood, pandera_schema_to_dagster_type extracts descriptive metadata from the Pandera schema and packages it into a TableSchema, which is attached to the returned DagsterType.
StockPricesDgType = pandera_schema_to_dagster_type(StockPrices)
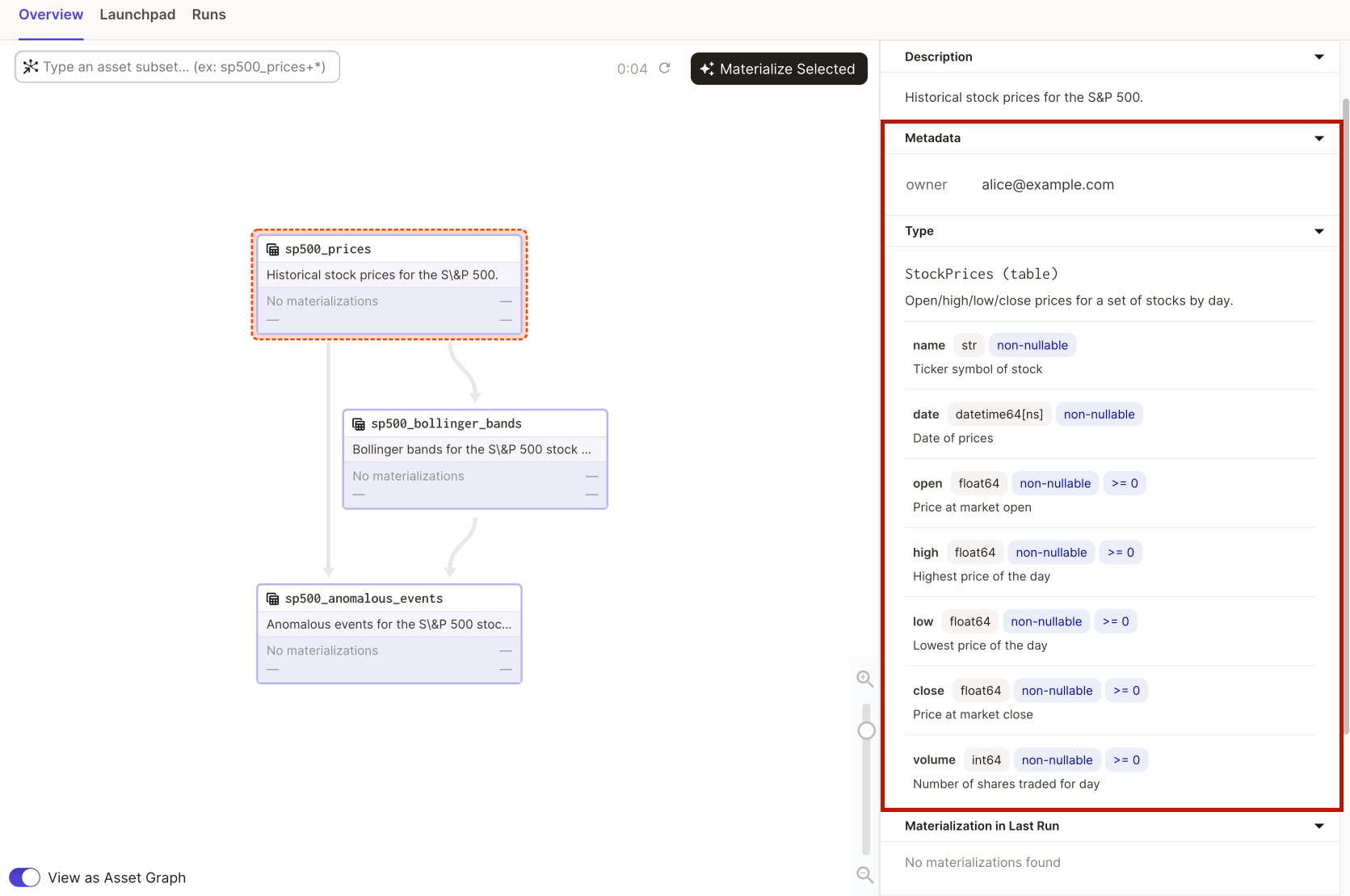
When the DagsterType is attached to an asset or output and rendered in Dagit, the schema information is also rendered:
@asset(
dagster_type=StockPricesDgType,
metadata={"owner": "alice@example.com"},
)
def sp500_prices():
"""Historical stock prices for the S&P 500."""
return load_sp500_prices()

If you’re familiar with our existing extension library dagster-pandas, you may be wondering how this relates to dagster-pandera. The two extension libraries have significant overlap-- both expose a type factory function that allows you to attach dataframe schema information to Dagster Types. The two most salient differences are:
dagster-pandasexposes its own schema definition API and implements its own validation logic. dagster-pandera outsources both schema definition and validation to pandera.- Only
dagster-panderaattaches rich schema information (i.e. using the Table Schema API) as metadata to Dagster Types. With dagster-pandas, some schema information is attached to the generated Dagster types, but it’s only a textual description of the schema.
We recommend users trying out a Dagster/Pandas integration for the first time go with dagster-pandera-- we’ve decided that it’s better to rely on first-class dedicated Pandas validation libraries like Pandera than to maintain our own dataframe validation logic. If we get the positive feedback on dagster-pandera we’re hoping for, we’ll deprecate dagster-pandas in the next release and fully focus on dagster-pandera and integrating with other third-party validation libraries. If you’d like to learn more, check out the dagster-pandera guide and the Bollinger example in the Dagster repo.


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


Dagster 1.7: Love Plus One


- Name
- Fraser Marlow
- Handle
- @frasermarlow

Dagster 1.6: Back to Black

- Name
- Sandy Ryza
- Handle
- @s_ryz

Dagster 1.5: How Will I Know?

- Name
- Yuhan Luo
- Handle
- @yuhan