
Build. Observe. Scale.
Dagster is the unified control plane for your data and AI Pipelines, built for modern data teams. Break down data silos, ship faster, and gain full visibility across your platform.




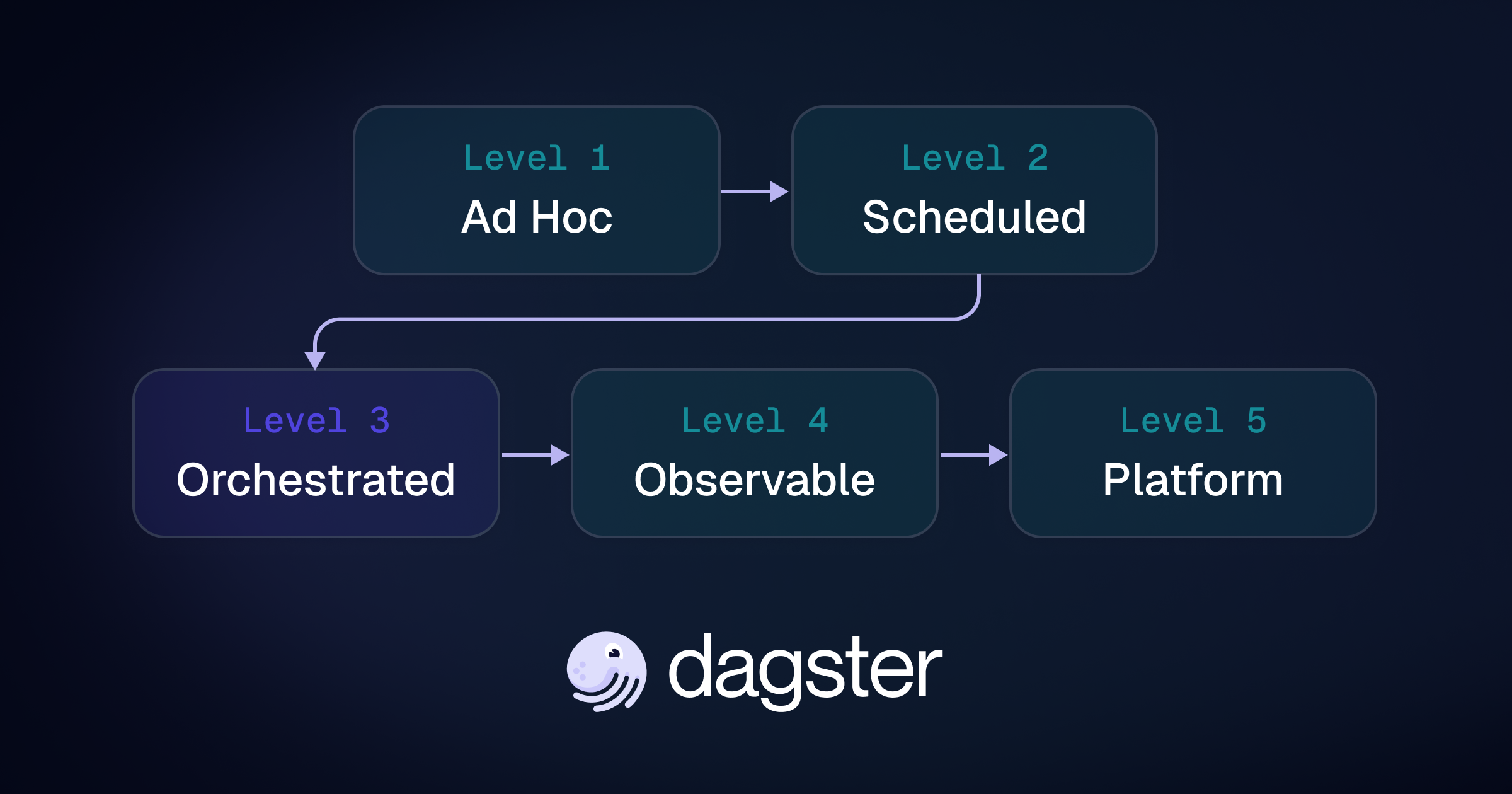
Modern orchestration for modern data teams
Dagster is a data-aware orchestrator that models your data assets, understands dependencies, and gives you full visibility across your platform. Built to support the full lifecycle from dev to prod, so you can build quickly and ship confidently.


Integrated with your stack
Dagster is designed to work with the tools you already use. Python scripts, Snowflake, dbt, Spark, Databricks, Azure, AWS and more. Avoid vendor lock-in with an orchestrator that allows you to move workloads to where it makes sense. And with Dagster Pipes, you get first-class observability and metadata tracking for jobs running in external systems.

Why high-performing data teams love Dagster
Unified data-aware orchestration
Unify your entire data stack with a true end-to-end data platform that includes data lineage, metadata, data quality, a data catalog and more.
A platform that keeps you future-ready
Dagster lives alongside your existing data stack seamlessly. Eliminate risky migrations while modernizing your platform, so whether you're building for analytics, ML, AI or whatever's next, you're covered.
Velocity without trade-offs
A developer-friendly platform that helps you ship fast, with the structure you need to scale. Modular and reusable components, declarative workflows, branch deployments, and a CI/CD-native workflow, it's the orchestrator that grows with your team, not against it.
Everything you need to build production-grade data pipelines
Dagster isn’t just an orchestrator—it’s a full development platform for modern data teams. From observability to modularity, every feature helps you ship data products faster.

Data-aware orchestration
Dagster orchestrates data pipelines with a modern, declarative approach. With its data-aware orchestration, it intelligently handles dependencies, supports partitions and incremental runs, and ensures reliable fault-tolerance so your teams deliver faster, while minimizing downtime and failures.
A data catalog you won't hate
Dagster's integrated catalog provides a unified, comprehensive view of all your data assets, workflows, and metadata. It centralizes data discovery, tracks lineage, and captures operational metadata so teams can quickly locate, understand, and reuse data components and pipelines across teams.

Data quality that’s built in, not bolted on
Data quality in Dagster is embedded directly into the code. With built-in validation, auomated testing, freshness checks, and observability tools, Dagster ensures data teams can provide consistent, accurate data at every stage of the pipeline. Proactively identify and resolve data quality issues before your stakeholders do.

Cost transparency at your fingertips
Dagster provides clear visibility into your data platform costs, enabling teams to monitor and optimize spending. By surfacing insights about your resource utilization and operational expenses, Dagster empowers data teams to make better decisions about infrastructure, manage budgets effectively, and achieve greater cost-efficiency at scale.
“The asset-based approach of orchestration massively reduces cognitive load when debugging issues because of how it aligns with data lineage.”

“Dagster is a flexible one- stop-shop for everything you need to build data transformation pipelines.”

“Defining assets in code means data pipelines are declarative, which minimizes the effort needed to schedule & materialize a complex DAG.”

“Dagster acts as a central plane for understanding data lineage, monitoring asset states, and orchestrating pipelines to update them.”
Orchestrate Smarter,
Scale Faster with Dagster.
Automate, monitor, and optimize your data pipelines with ease. Get started today with a free trial or book a demo to see Dagster in action.

The latest from the labs
The latest news, content, and resources from the Dagster Labs team.
.jpg)
.png)
.jpg)


.png)

